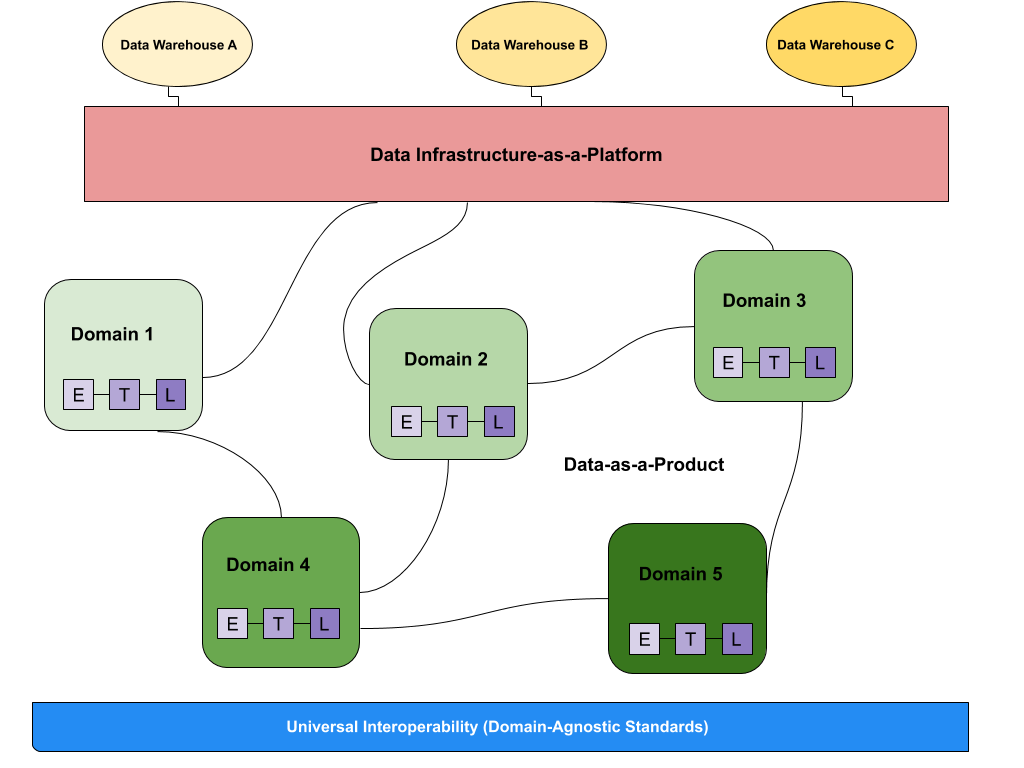
The data mesh, literally "net of data", refers to a big data processing system, with a very specific architecture whose key word is: decentralisation.
Conceptualised in 2019 by Zhamak Dehghani of Thoughtworks, the data mesh proposes an architecture where each data domain of the company (e.g. customers, products, etc.) is managed independently by the team responsible for it (domain-oriented approach). This data is offered as self-service via APIs, as if it were a ready-to-use product. This should result in time savings (reuse), agility (use as a service) and space savings (no duplication) in its processing and analysis. It can be summarised as "a change in self-service data architecture, treating data as a product".
* Image Source : Towards Data Science